مجموعة البيانات Datasets
مجموعة البيانات هي اي محموعة من البيانات يتم تجميعها. عادة في اي مشكلة ML نقوم بتقسيم البيانات التي نجمعها الى مجموعتين رئيسيتين: بيانات التدريب Training Data set و بيانات الاختبار Test Data set. و ذلك لحل مشكلة التعميم و للتأكد من ان النموذج سيؤدي بشكل جيد مع البيانات في الواقع.
مجموعة بيانات التدريب Training Data set
هي البيانات التي يستخدمها المحسن Optimizer لتحسين دقة النموذج ساعة التدريب، وهي البيانات التي تحدد المتغيرات في النموذج.
مجموعة بيانات الاختبار Test Data set
هي جزء من مجموعة البيانات التي تم تجميعها (الجزء الاخر يكون بيانات التدريب)، وهي تقوم بدور بيانات الواقع. حيث يقوم النموذج يتدريب نفسه باستخدام بيانات التدريب، ثم نقيس دقته بكلا من بيانات التدريب و بيانات الاختبار، فاذا كانت الدقة جيدة في الحالتين نستطيع ان نعتمد على ذلك النموذج.
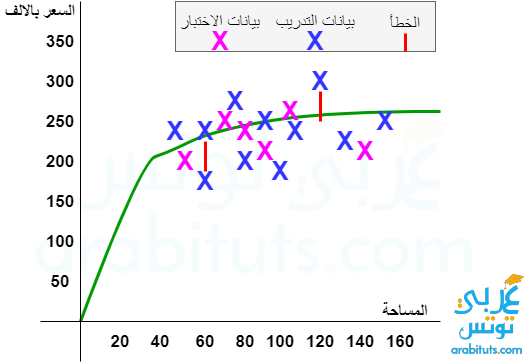
الملائمة الضعيفة Underfitting
احد المشاكل التي نقابلها اثناء تدريب النموذج هو ان معادلة او خوارزمية النموذج بسيطة و لا تعطي دقة كافية اثناء تدريب النموذج و بالطبع عند الاختبار. هناك عدة اسباب لتلك المشكلة، احد تلك المشاكل هي ان عدد الملامح غير كافي. فمثلا في مثال الشقق، قد تكون مساحة الشقة كبيرة لكن عدد الفرف اقل فهذا بالطبع ينعكس على سعرها وايضا دور او مستوى الشقة فالادوار الارضية والاخيرة دائما اقل من مثيلاها. لذا قد نحتاج عدد اخر من الملامح لبناء نموذج اقوى.
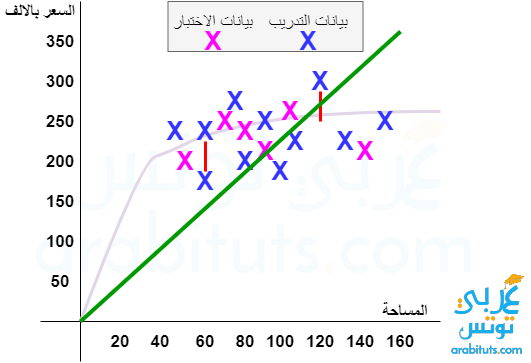
تعدد الميزات Multi-Feature
في مثال التنبوء بسعر الشقق كان عدد الميزات هو واحد فقط وهي مساحة الشقة. لكن في كثير من المشاكل الواقعية، يوجد اكثر من ميزة للتنبوء وبالطبع هذا يساعد غالبا على تحسن الدقة بشكل كبير.
بالطبع التعامل مع الميزات المتعددة Multi-Features يزيد من تعقيدات خوارزميات النماذج فمثلا اذا كان هناك ملمحان قد تكون دالة النموذج f(x,y) = a . x + b . y + c . x^2 + d . y^2 + g اصبح الان عدد المتغيرات التي يتدرب عليها النموذج اكثر وهم a و b و c و d و g، كما ان المحسن Optimizer سيحتاح وقت اكبر للوصول لافضل نموذج. لكن في المقابل نحصل على نموذج افضل.
الملائمة المفرطة Overfitting
اثناء تدريب النموذج نتعرض لما يعرف بالملائمة المفرطة Overfitting وهو ان النموذج يحاول ان يلائم بيانات التدريب training data بافراط مما يجعل النموذج غير اعتمادي وتكون دقته مثلا مع بيانات الاختبار test data اقل بكثير.
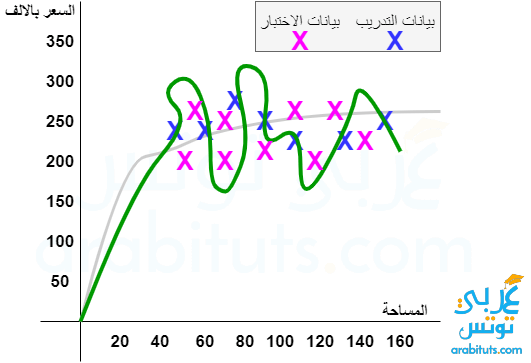
احد اسباب تلك المشكلة قد تكون تعدد الملامح multi feature خصوصا لو استخدمنا features غير مناسبة، او ليست ذات علاقة و بالتالي قد نقلل عدد الملامح.
لكن ليس دائما ما يكون هذا هو السبب لذا نستخدم ما يعرف بالتسوية Regularization.
التسوية Regularization
التسوية هو عبارة عن معامل نستخدمه اثناء تدريب النموذج ويهدف الى الحد من الملائمة المفرطة.