كما ذكرنا لحل مشاكل تعلم الالة، هناك مجموعة من الخطوات التي نسير عليها لنصل الى افضل نموذج model وهو كالاتي
- تعريف المشكلة.
- تحليل و تجهيز البيانات.
- اختيار الخوارزمية.
- تدريب الخوازمية
- تقييم الخوارزمية.
تعريف المشكلة.
المشكلة هو التعرف على الارقام العشرية المكتوبة بخط الايد. تتكون مجموعة البيانات التي لدينا من مجموعة من الصور تمثل كل قراءة رقم مكتوب يدويا من 0 الى 9 والمطلوب بناء نموذج لديه القدرة للتعرف على الارقام من الصور. كل صورة تأتي بمقاس 8×8 وكل نقطة تأخذ قيمة من 0 الى 16 لتمثل كثافة الكتابة كما بالشكل:

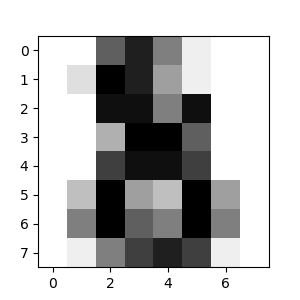
من التعريف نستنتج ان المسألة هي تصنيف classification الى 10 اصناف وهي شكل الارقام من 0 الى 10. وان القراءات او الملامح features تتكون من 64 عنصر (8 * 8) كل منها عبارة عن رقم من 0 الى 16.
تحليل و تجهيز البيانات.
اولا نحتاج الى الى تحميل المكتبات التي نستخدمها و مجموعة البيانات
تشغيلimport numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split digits = datasets.load_digits()
توفر مكتبة scikit learn او اختصارا sklearn العديد من مجموعات البيانات المشهورة التي نستطيع استخدامها ومنها مجموعة بيانات الارقام العشرية digits ويتم تحميلها كما بالكود.
لبداية فهم البيانات نحتاج ان نعرض عينة من البيانات و ملخص عنها
تشغيل
digits_df = pd.DataFrame(digits.data)
digits_df['digits'] = digits.target
print(digits_df.head())
print("-----------------------------------------------------------------")
print("-----------------------------------------------------------------")
print("-----------------------------------------------------------------")
images = digits.images
numbers = digits.target
print(images[0])
_, axes = plt.subplots(1, 5)
#images_and_labels = list(zip(digits.images, digits.target))
for i in range(5):
axes[i].set_title('Training: %i' % numbers[i])
axes[i].imshow(images[i] ,cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
نجهز بيانات التدريب والاختبار من مجموعة البيانات المتاحة كالاتي
تشغيل
X = digits_df.drop('digits', axis=1)
y = digits_df['digits']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
تستخدم الدالة train_test_split الى تقسيم البيانات بطريقة عشوائية (حتى تكون البيانات موزعة بشكل عادل بين مجموعة التدريب ومجموعة الاختبار) و بنسبة محددة (30% في هذا المثال). البيانات التي ترجعها دالة train_test_split منقسمة الى 4 اجزاء
- X_train : هي قياسات التدريب اي 64 رقم تتراوح قيمتهم من 0 الى 16 يمثلوا الصورة لمجموعة بيانات التدريب .
- ْX_test : هي قياسات التدريب اي64 رقم تتراوح قيمتهم من 0 الى 16 يمثلوا الصورة لمجموعة بيانات الاختبار.
- y_train: هي نتائج التدريب اي الرقم المكتوب يدويا من 0:9 لمجموعة بيانات التدريب.
- y_test: هي نتائج التدريباي الرقم المكتوب يدويا من 0:9 لمجموعة بيانات الاختبار.
اختيار وتدريب الخوارزمية*
سنحاول اختبار عدد من خوازميات الانحدار المشهورة لمعرفة ايهما يحقق افضل نتائج لنختاره، نستطيع استخدام خوازميات التصنيف كما في درس زهرة السوسن iris problem. لكن الان سنجرب الشبكات العصبية NN.
نموذج LogisticRegression
تشغيل
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
LR_model = LogisticRegression(max_iter = 3000)
LR_model.fit(X_train,y_train)
prediction=LR_model.predict(X_test)
print('The accuracy of the Logistic Regression is',metrics.accuracy_score(prediction,y_test))
NN
تشغيل
from sklearn.neural_network import MLPClassifier
from sklearn import metrics
NN_model = MLPClassifier(200)
NN_model.fit(X_train,y_train) # we train the algorithm with the training data and the training output
prediction=NN_model.predict(X_test) #now we pass the testing data to the trained algorithm
print('The accuracy of the NN is',metrics.accuracy_score(prediction,y_test))
تسهل علينا مكتبة sklearn انشاء نموذج NN باستخدام()MLPClassifier الرقم داخل دالة الانشاء constructor هو عبارة عدد الخلايا ف الطبقة الداخلية/ المختفية Hidden Layer، نستطيع حتى زيادة عدد الطبقات كالاتي (100,200,100)MLPClassifier بذلك عرفنا 3 طبقات تحتوي على عدد خلايا 100 ثم 200 ثم 100 بالترتيب.